
How Many Images Do I Need for My Computer Vision Model? (2023 Guide)
This is one the big questions all of us ask ourselves when training an artificial neural network for a specific computer vision task. But is there an exact answer?
As with all in life, it depends. A computer vision model can work very well with just 100 images, 1000 images or 1 million images. It depends on the nature of your data and the level of accuracy you need to achieve.

Generally, the more data, the better the AI model.
At Theos we always recommend our clients to start with just 100 images, then train an initial model and see how it performs. If they need more accuracy, add another 500 images and retrain, then 1000, then 5k, 15k and so on. Luckily, after each iteration they can leverage their improved model with our magical Autolabeler to help them label the next batch of images 100 times faster than doing it manually.
Your training data should be as close as possible to the data on which you will be making predictions. For example, if your use case involves low-resolution images from CCTV or cell phone cameras, your training data should be also composed of low-resolution images. In general, you should also consider providing multiple angles, resolutions, and backgrounds. The more variety you expect your AI to see in production, the more variety you should add to your dataset.
If when you run your model in production, you consistently get low confidence scores for some of the classes, the low-scoring images should be added to your dataset to retrain your model and improve its performance. After adding more data in this informed manner, you will inevitably get a model that not only scores higher, but also understands all the possibilities of the environment it finds itself in, and models the true distribution of your data.
What About the Nature of the Data?
The nature of your data plays a big role on how hard it will be for your AI to learn how to recognize patterns in it, the more complex the patters, the more examples it will need to correctly learn to recognize them and achieve high accuracy.
Simple Patterns
Let’s take a look at a model that works very well with a dataset composed of just 100 images.

Faces dataset created with Theos AI
As it turns out, human eyes, noses and mouths are really easy for an AI to learn to detect. With just 100 images you can effectively train an AI to be really good at detecting these human facial features.
Why would this be the case?
Well, if you think about it, eyes are basically circles at their essence. Sure, they have different colors and might be slightly different from person to person, but overall they are composed of a very simple pattern and have very little variation when not looked up close. The same is true for noses, as they have a triangular shape and 2 circles at the bottom. Mouths are also very simple and common between people. Simple patterns require fewer examples to be learned correctly.
Complex Patterns
Now let’s take a look at an example in which an AI will probably struggle to find patterns because of their complexity.
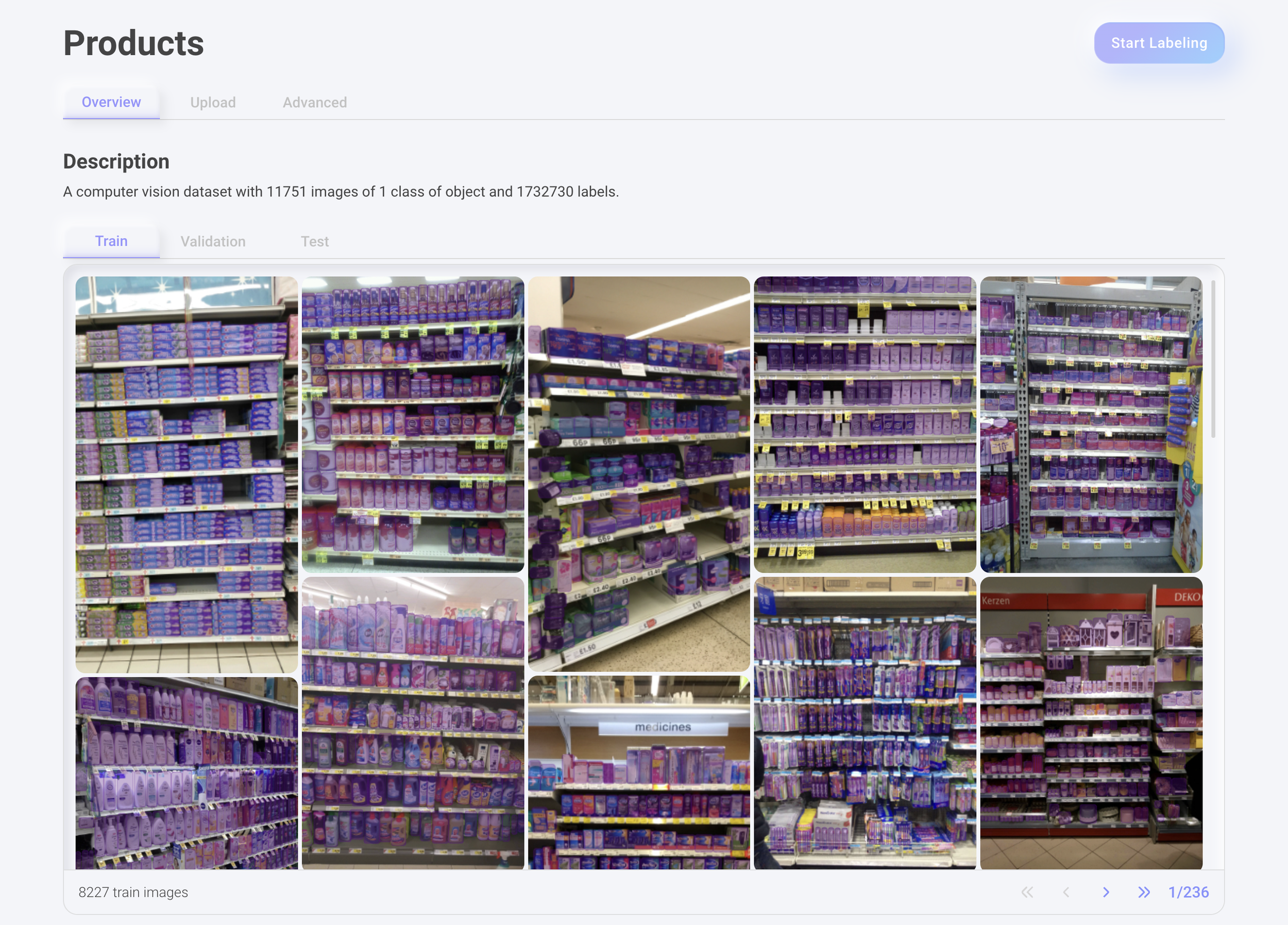
Products dataset imported to Theos AI
Imagine we are trying to create an AI model to detect and count products in shelves of supermarkets and stores in order to automatically keep track of stock and notify employees to refill the shelves when they’re running out of it.
In our stock detection system we don’t really care about differentiating between all the brands of the products, as the supermarket management already knows which products correspond to which shelves, so we need only 1 class, the product class. When a security camera detects a low number of products in a given shelve, it alerts all employees though a mobile app notification, and one of them goes to check it out and refills it accordingly.
This sounds easy right? we have only 1 class after all.
But, the reality is that the difference between all possible products is astronomical. Think about all the different shapes, colors and sizes of all the products you have ever seen in a supermarket. Mapping all these extremely different and complex patterns into 1 class is quite hard for an AI to do. This is why it takes a dataset of 11k images and almost 2 million labels to effectively train an AI model that can detect all these patterns with high accuracy.
In Conclusion, How Big Should the Dataset Be?
Generally speaking, the more data, the better. This is almost always true. However, an exception to this rule would be that if adding more examples leads to a class imbalance, this is a big problem because your AI will start to confuse classes and may not even recognize the underrepresented ones. You should always strive to have a healthy class balance, meaning all your classes have roughly the same number of labels. Be smart about selecting the correct images in order to maintain a healthy class balance.
The amount of data needed to train a good machine learning model depends on different factors:
The number of classes: the more classes you have, the more examples per class you will need.
The complexity/diversity of classes: humans can quickly learn to distinguish between the taste of beer and wine, with only a few examples. One will have to taste many wines much more frequently to distinguish between 5 or 6 different types, and for many humans it will be a very hard challenge to learn to distinguish between 50 flavours of red wines. At least one will have to practice a lot. Similarly, artificial neural networks can quickly distinguish between cats and dogs, but will need many more examples to recognize 300 different species of animals.
But as we said earlier, don’t worry about it too much. Just start with 100 images, train an initial model, see how it performs, and add more images if needed. Just like with regular software, you should make an MVP (minimum viable product) of your AI, and iterate as fast as possible.
If you need to create a state-of-the-art computer vision model, you can take a look at our AI development platform. With Theos you will be able to create your own artificial intelligence without the need to be an expert engineer in the subject. Upload images, create new labels or import them from various formats, monitor your dataset’s class balance and other important statistics to constantly improve its quality, then train your AI in just a single click and deploy your model into production with one last click. Finally, use your AI in your software by adding only 10 lines of code. Yes, is that simple.
You can try it now, it’s free forever.